
Hey everyone, and welcome back to the channel! Today, we’re diving into CogVideoX, a local solution for video generation that has piqued my interest. If you’ve been seeking an alternative to platforms like Runway or Cling and prefer something you can run locally, this might be the perfect solution for you.
What is CogVideoX?
CogVideoX initially emerged as a text-to-video model, but it has recently expanded to include image-to-image capabilities. The results are quite impressive, to the point where they might even rival those of Luma. I was pleasantly surprised by the quality of animations generated from the images I input, often exceeding what I’ve achieved with Luma in previous experiments. That said, I haven’t yet tested Luma’s new 1.5 update, which could potentially offer considerable improvements.
Limitations
Despite its promising capabilities, CogVideoX comes with certain limitations. The model currently only supports a resolution of 480×720 pixels, meaning you can’t generate vertical videos or use any other resolutions. For practical usage, you’ll likely need to upscale the generated videos.
Getting Started with CogVideoX
To help you get started, I’m sharing a couple of videos I generated using the text-to-image function. However, today’s main focus will be on the image-to-image capabilities. The installation instructions I’ll provide are applicable to both scenarios.
Installation Instructions
We will be using ComfyUI for this installation. The process involves several steps:
- Access the Node Manager: Go to the Customs Node Manager and install the following node groups:
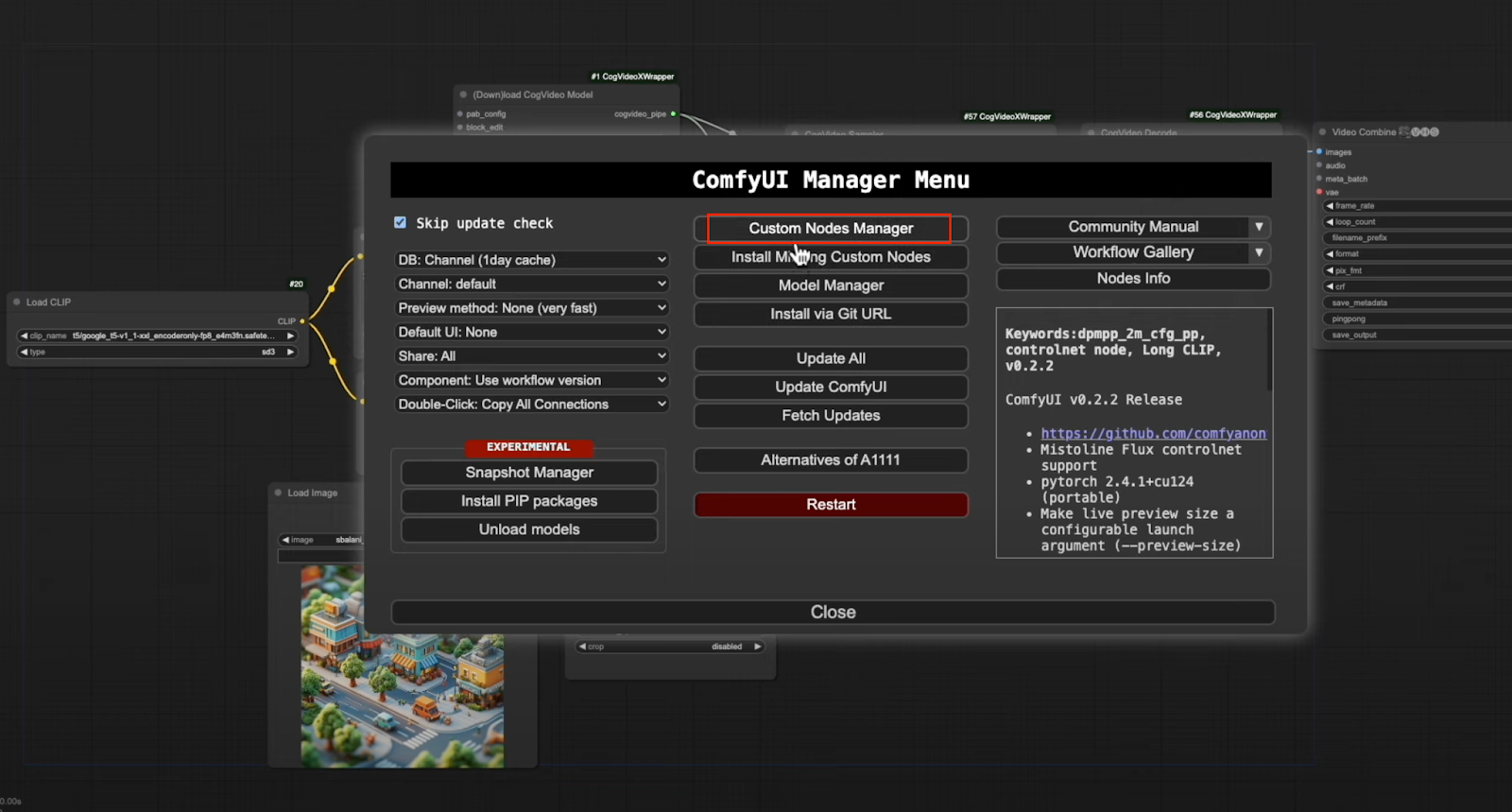
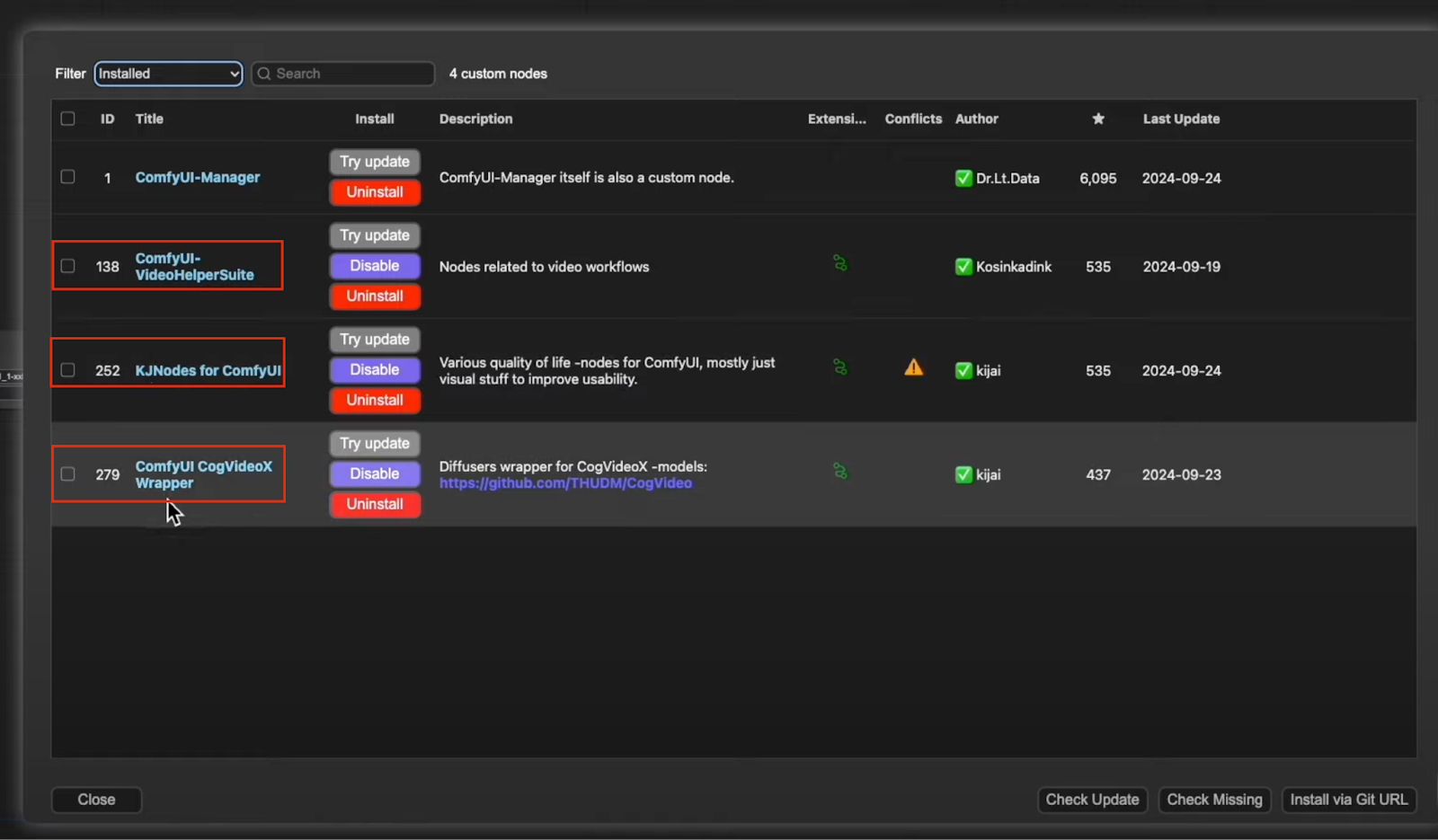
- ComfyUI Video Helper Suite
- KJ Nodes for ComfyUI
- ComfyUI CogVideoX Wrapper
- Drag in the JSON File: You can find the JSON file in the link below. Dragging it in will automatically identify any missing nodes.
- Configure the Workflow: After dragging in the JSON file, your workflow should look something like this:
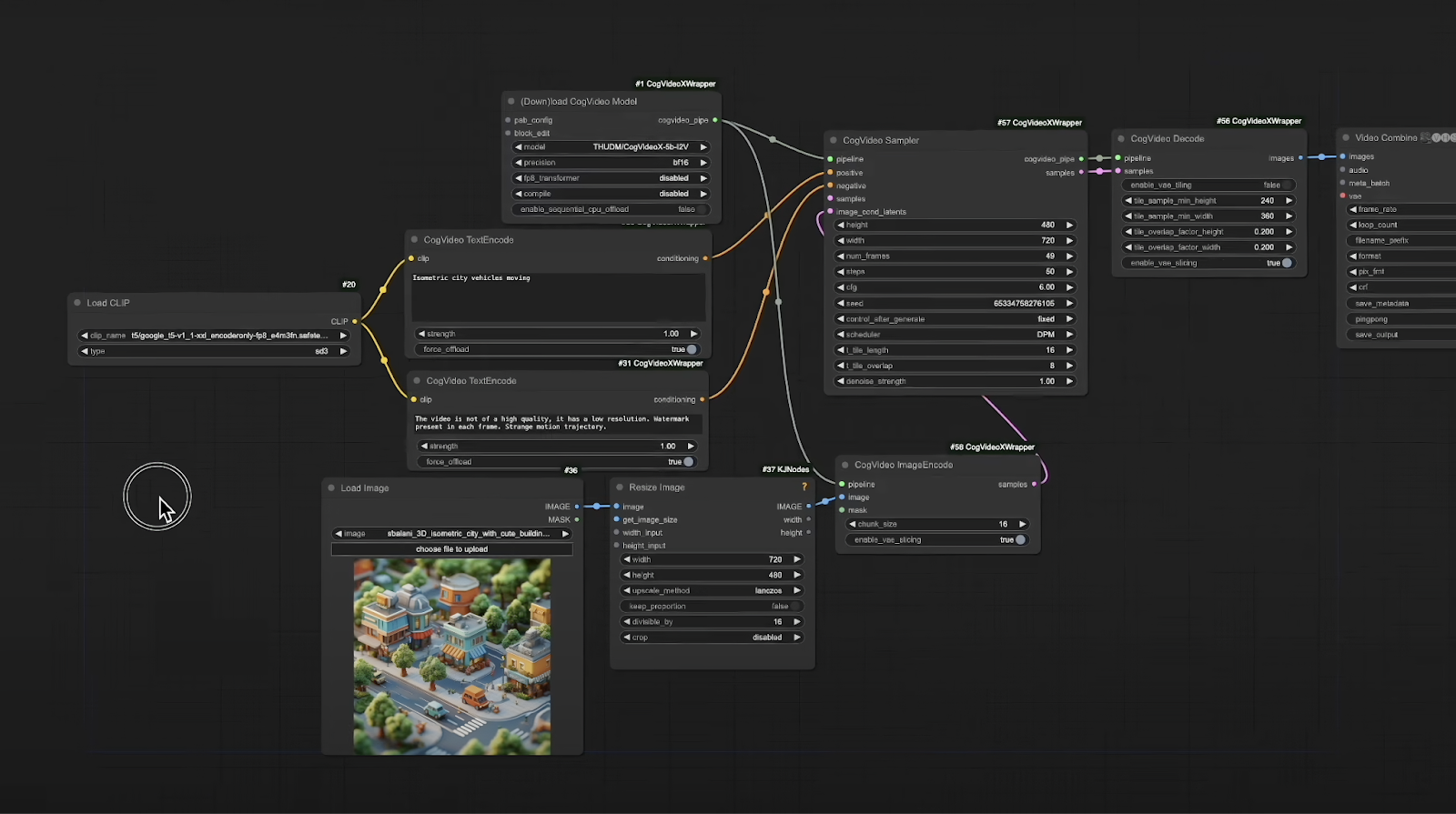
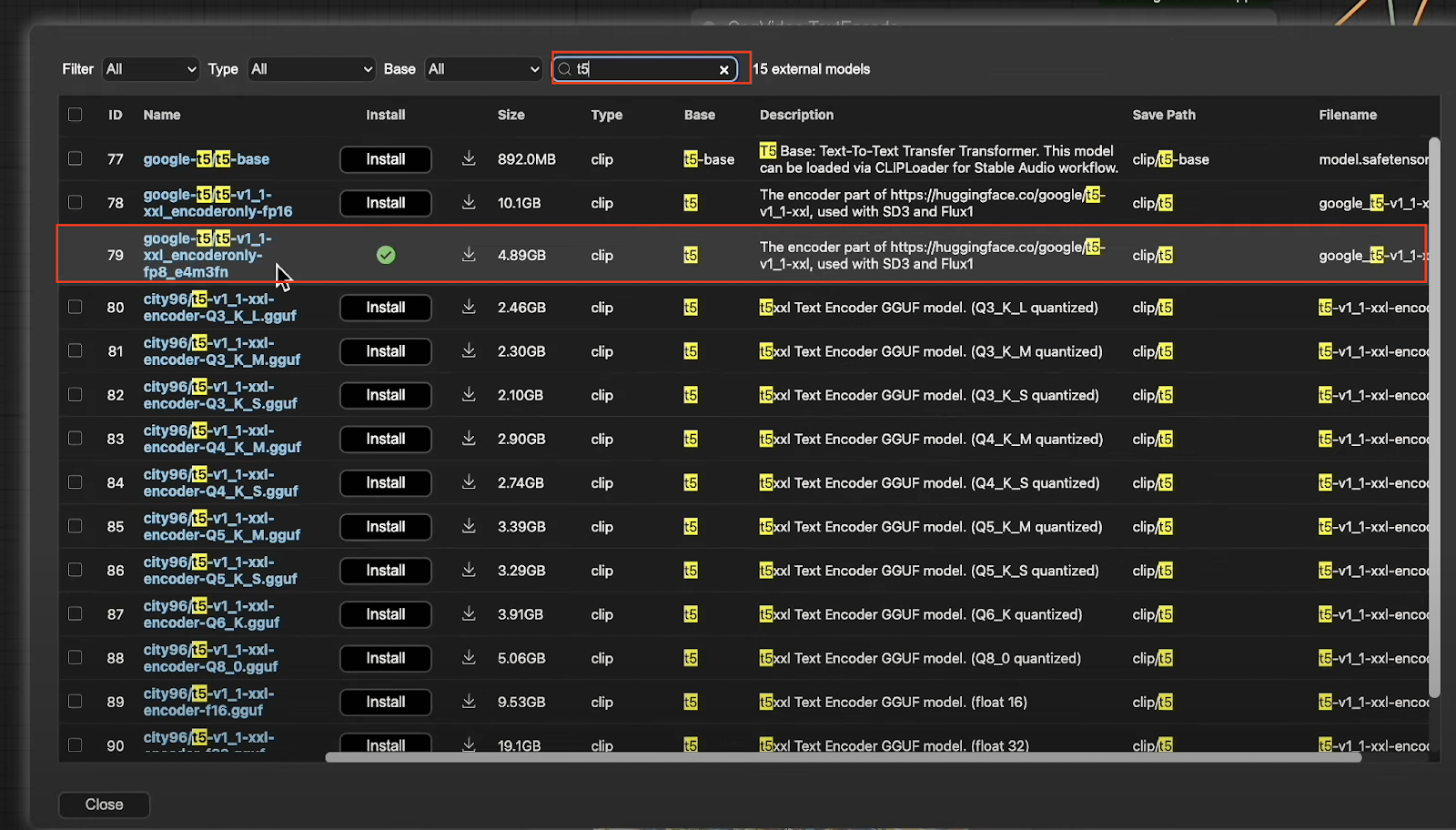
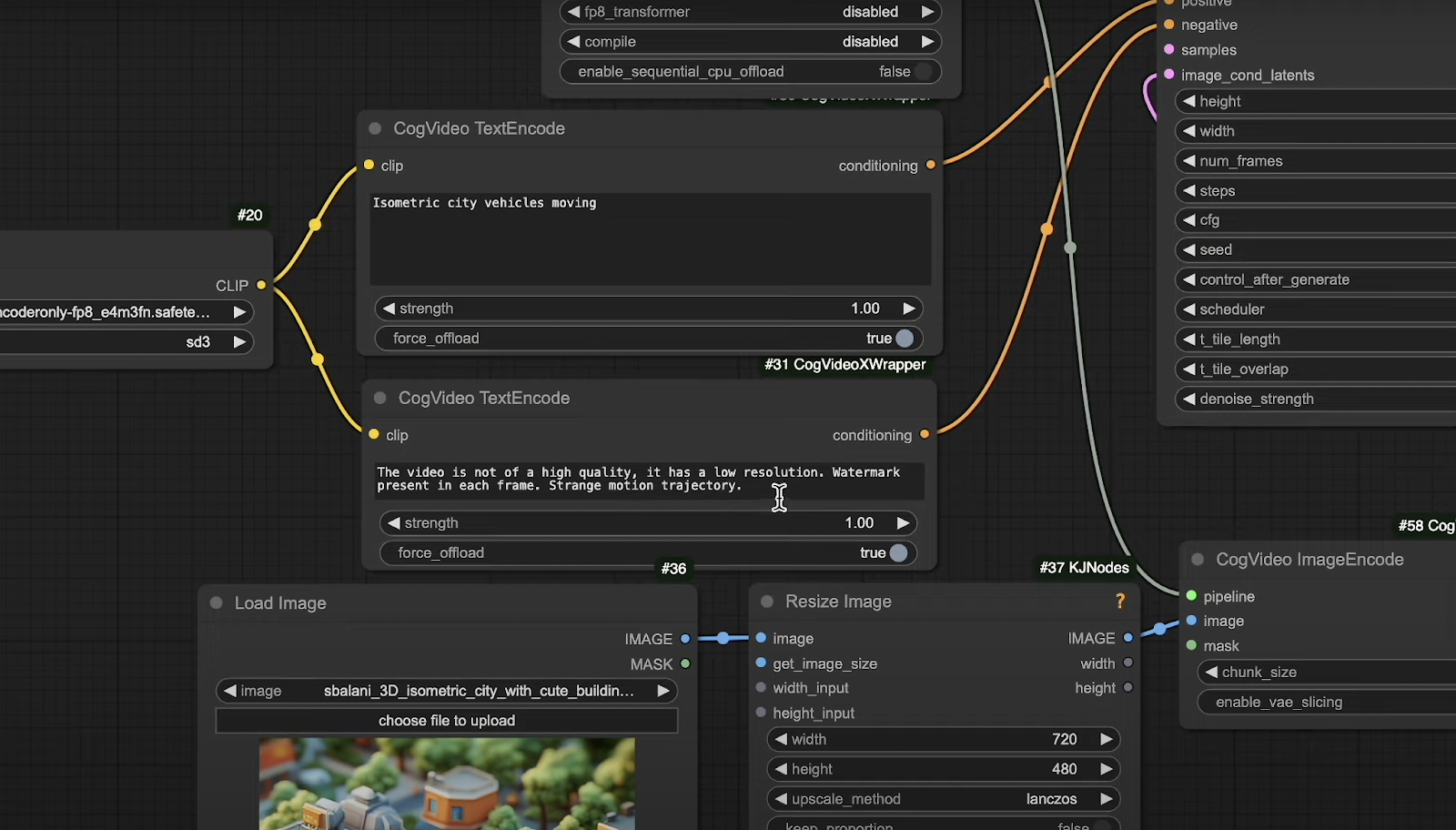
Load Clip: This works with the same T5 model used in Flux and Stable Diffusion version 3.

T5 Model: Accessible via the Model Manager by typing “T5”. You’ll find both FP8 and FP16 versions available.
Text Encoders: These are specific to CogVideoX, with one for the positive prompt and another for the negative prompt. The negative prompt comes pre-filled with conditions such as “this video is not of high quality,” “low resolution,” “watermark present in each frame,” and “strange motion trajectory.” You can adjust these settings as needed.
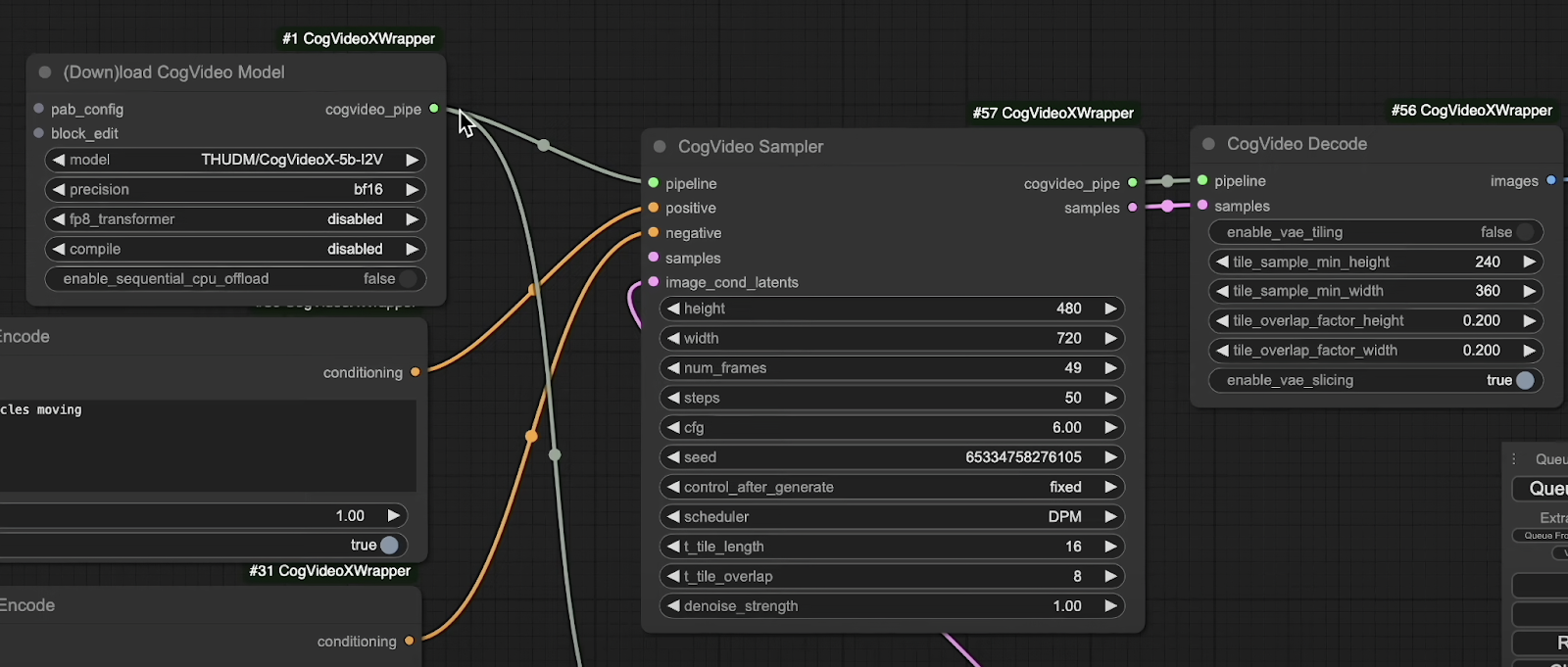
CogVideoX Sampler and Loader: The sampler allows for adjustments in frame count, generation steps, CFG, among other parameters. The loader node includes an option to download the desired Cog model if it isn’t already installed.
Video Decoder and Combiner: These components are essential for decoding and combining the generated frames into a cohesive video.
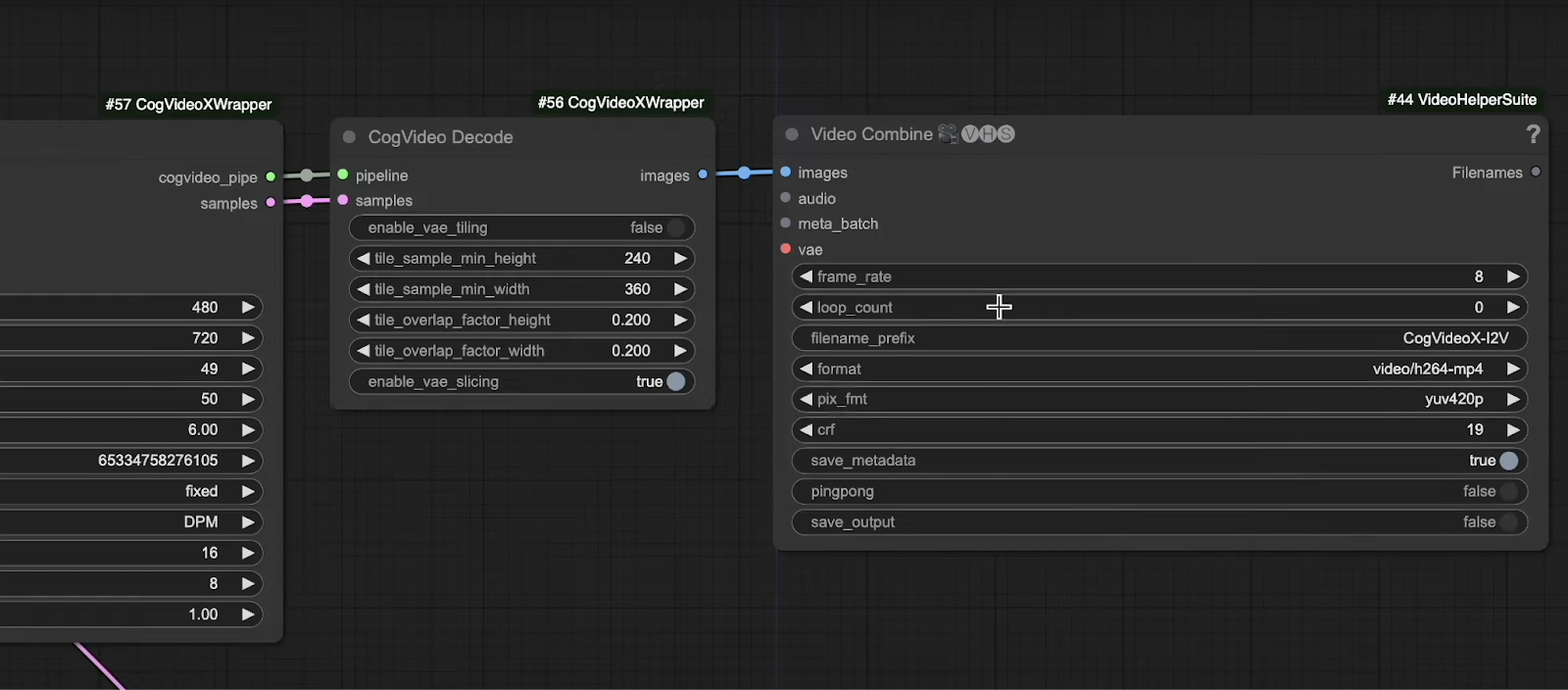
Image Input Resizer: This resizes your input image to fit CogVideoX’s dimensions. Although the image may stretch, you can resize it in a video editor afterward to achieve the desired aspect ratio and then upscale it.
Conclusion
This setup guide should help you get started with CogVideoX. If you encounter any issues, feel free to leave your comments below. As a special bonus, you can find JSON files for this workflow, the text-to-image workflow, and a lazy workflow (available exclusively to my Patrons) that simplifies the process by generating and animating the video within a single frame.
Here are a couple of videos I generated to demonstrate the process. Enjoy!
Your Thoughts?
What do you guys think? Will you be using CogVideoX? Did you find the results comparable or superior to any commercial models out there? I’m eager to hear your thoughts. Hopefully, we’ll see further advancements in resolution and video size options in the future, especially given that this model isn’t based on Stable Video.
If you found this guide helpful, please don’t forget to like and subscribe. I’ll catch you in the next video!