
Introduction
Stable Diffusion 3 has been out for about a day now, and initial impressions suggest it’s facing significant challenges, particularly in basic tasks like understanding human anatomy. However, when the model cooperates, it produces markedly superior images compared to SDXL: more detail, sharpness, and clarity. Despite these hurdles, the community has been proactive. After scouring various Discords and Reddits, I’ve compiled essential best practices, tips, and tricks for using Stable Diffusion 3. Admittedly, some methods are convoluted, but they are necessary to achieve the desired performance.
Detailed Prompts for Enhanced Results with ChatGPT
If you’ve tried prompting with SDXL or SD 1.5 using simple prompts, you might find that Stable Diffusion 3 struggles with the same approach. While you can achieve good images with basic prompts, the model tends to perform better with very verbose, descriptive, and long-winded prompts. This is where a large language model like ChatGPT can be incredibly useful. In fact, there are nodes available that interface directly with OpenAI’s ChatGPT, LLaMA, and other models, allowing you to transform simple descriptions into detailed prompts—perfect for use with Stable Diffusion 3.
For example, I started with a simple prompt: “anime woman drinking a cup of coffee.” Without the “anime” token, the resulting image was okay, but the issue with hand details was prevalent—a common problem with Stable Diffusion 3. A hand detailer is often required to fix these issues. The image did follow the prompt, but there was nothing particularly impressive about it.
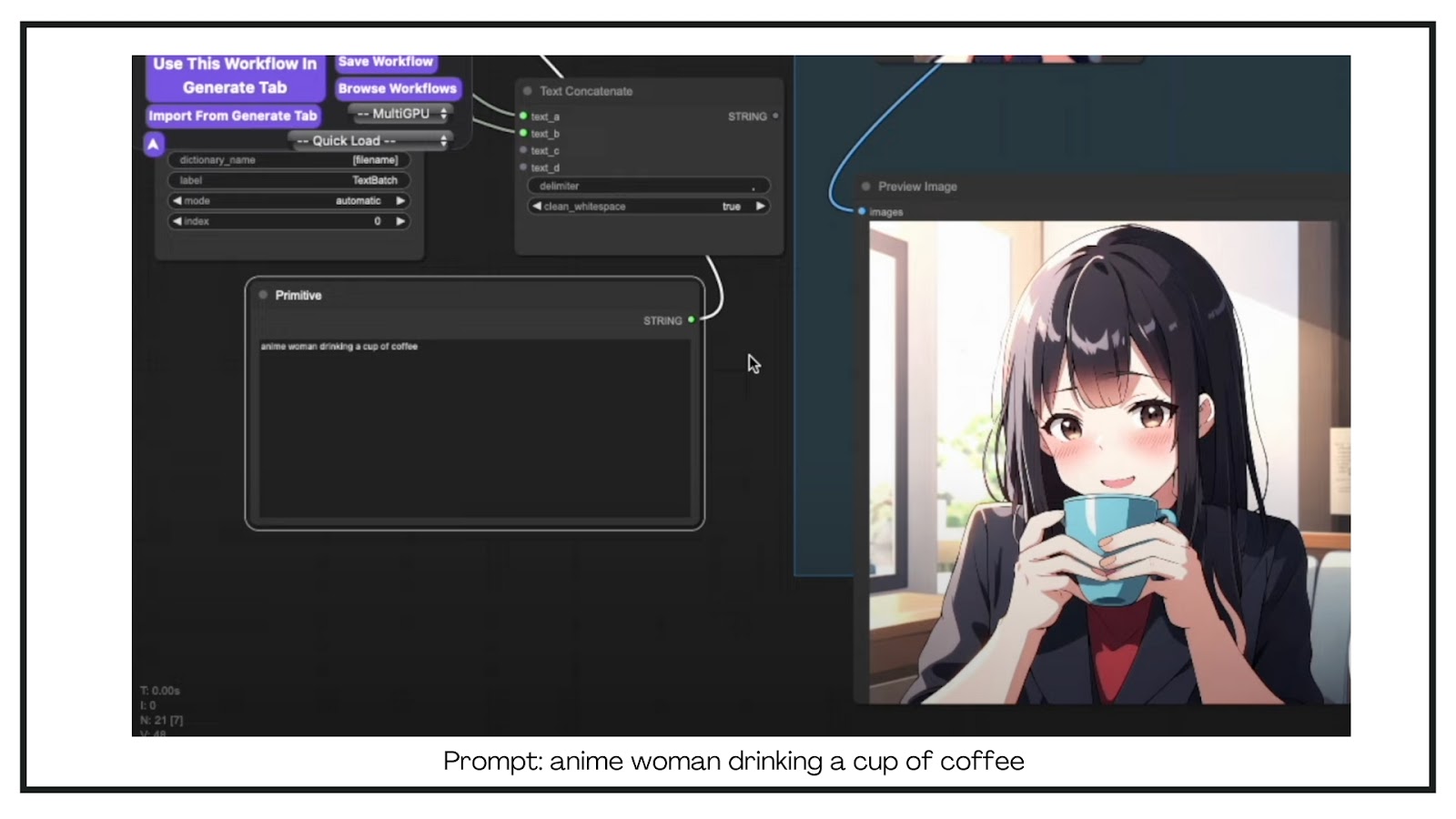
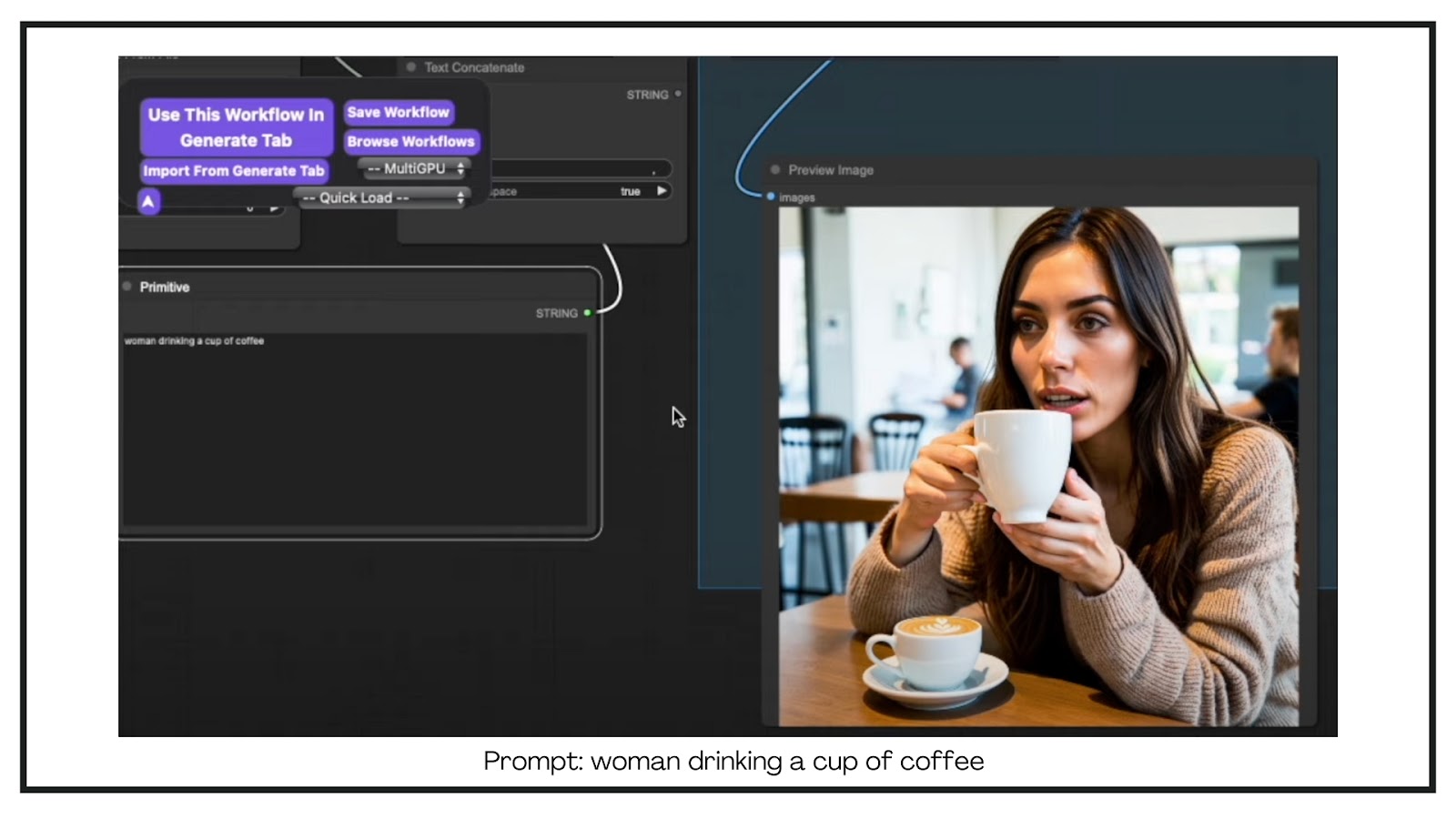
To enhance this, I used ChatGPT to generate a more detailed prompt. I instructed it to give me a detailed description based on my initial prompt. Here’s the refined prompt:
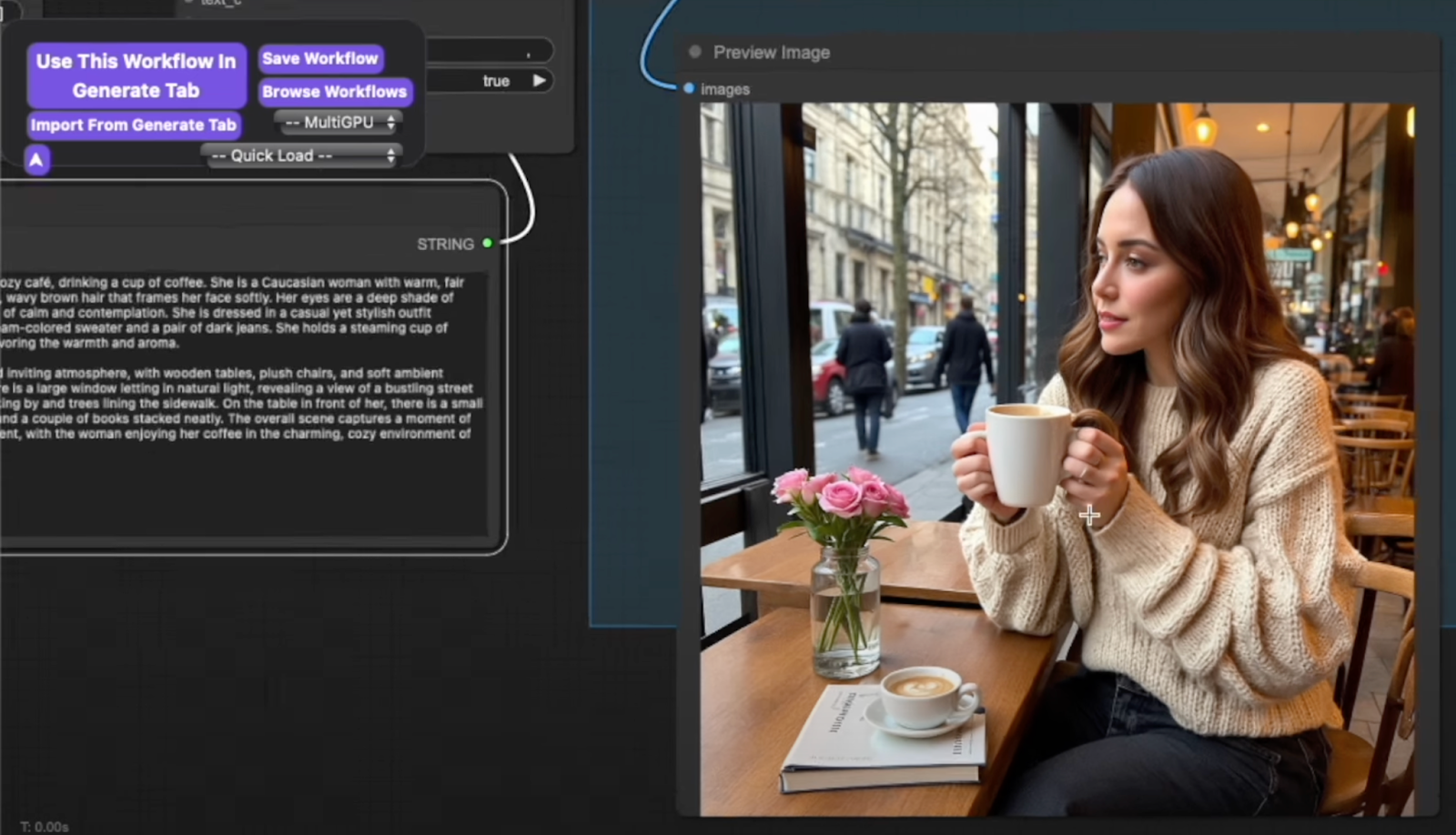
Prompt: “A woman sitting in a cozy cafe, drinking a cup of coffee. She is a Caucasian woman with warm fair skin and medium-length wavy brown hair…”
Result:
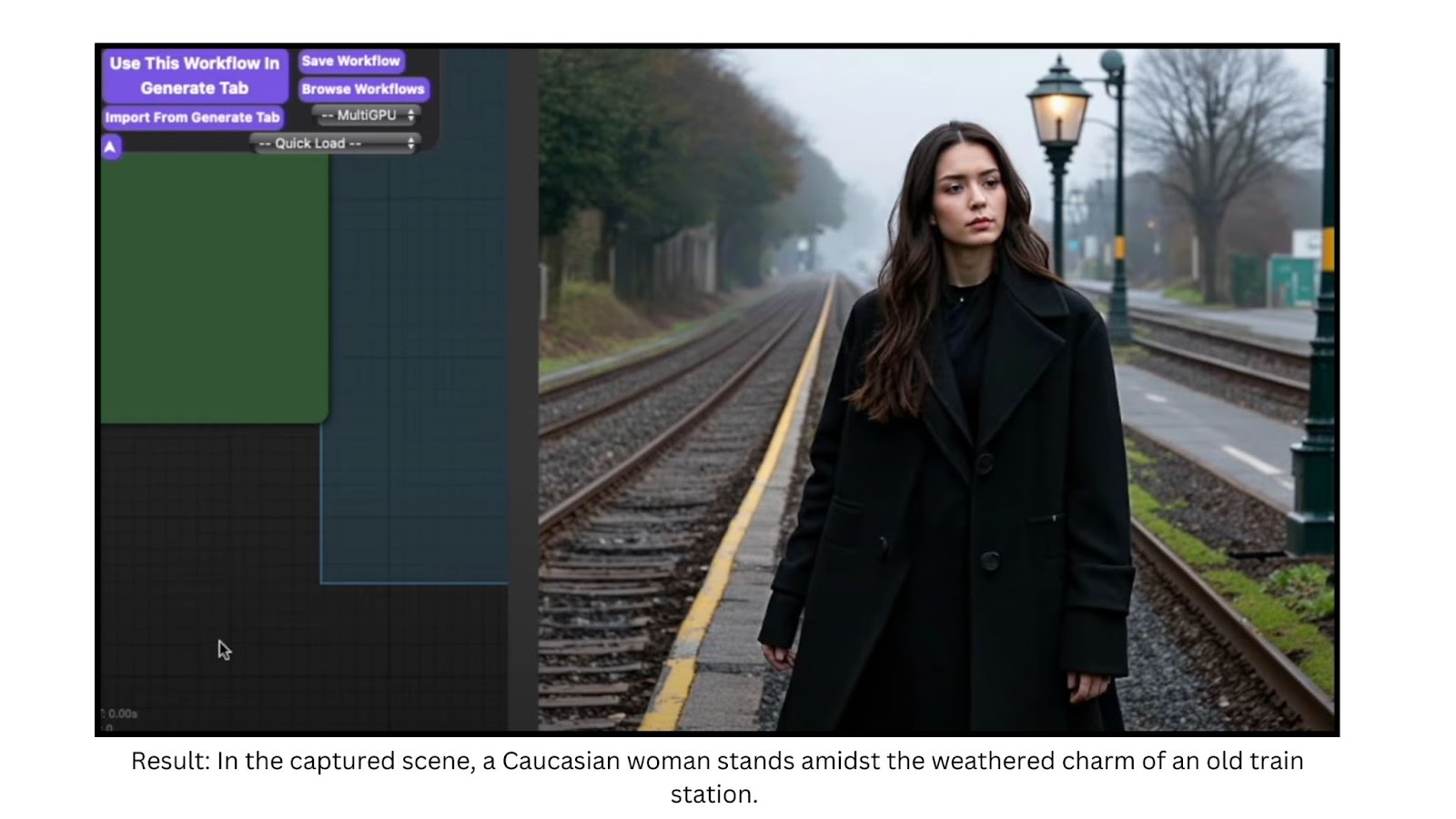
Here’s another example. I described a female character standing at a train station, including details about her character, attire, atmosphere, time period, and the station itself. The model struggled with some details, such as the ethnicity—I requested a Caucasian girl but got someone who appeared slightly more Asian. Additionally, the striking blue eyes specified in the prompt didn’t materialize. To address this, I applied tricks from older Stable Diffusion models, like adding elements in parentheses. This yielded a slightly better result, though the blue eyes were still missing and the face could benefit from a detailer. However, the anatomy and other details were decent.
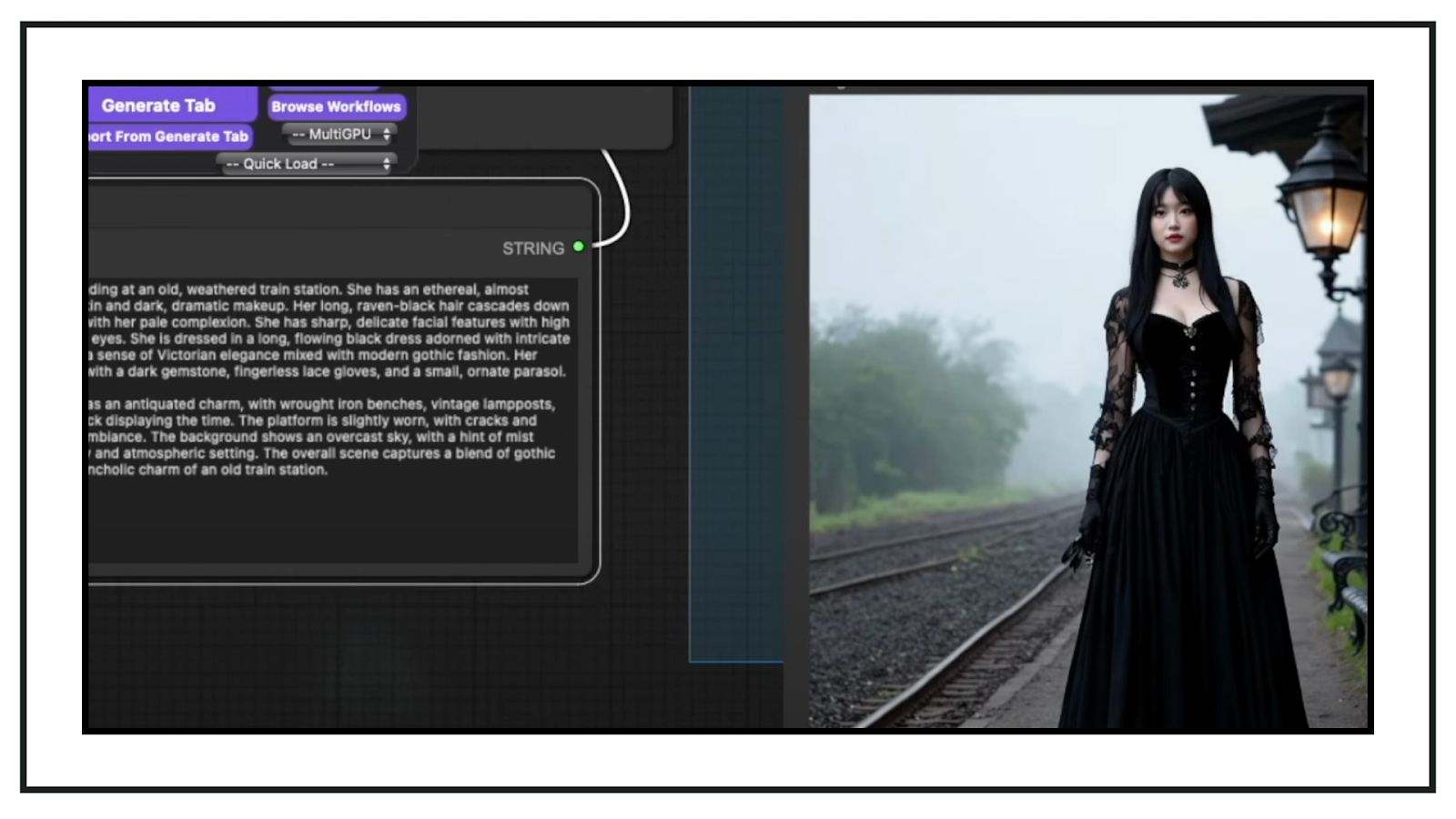
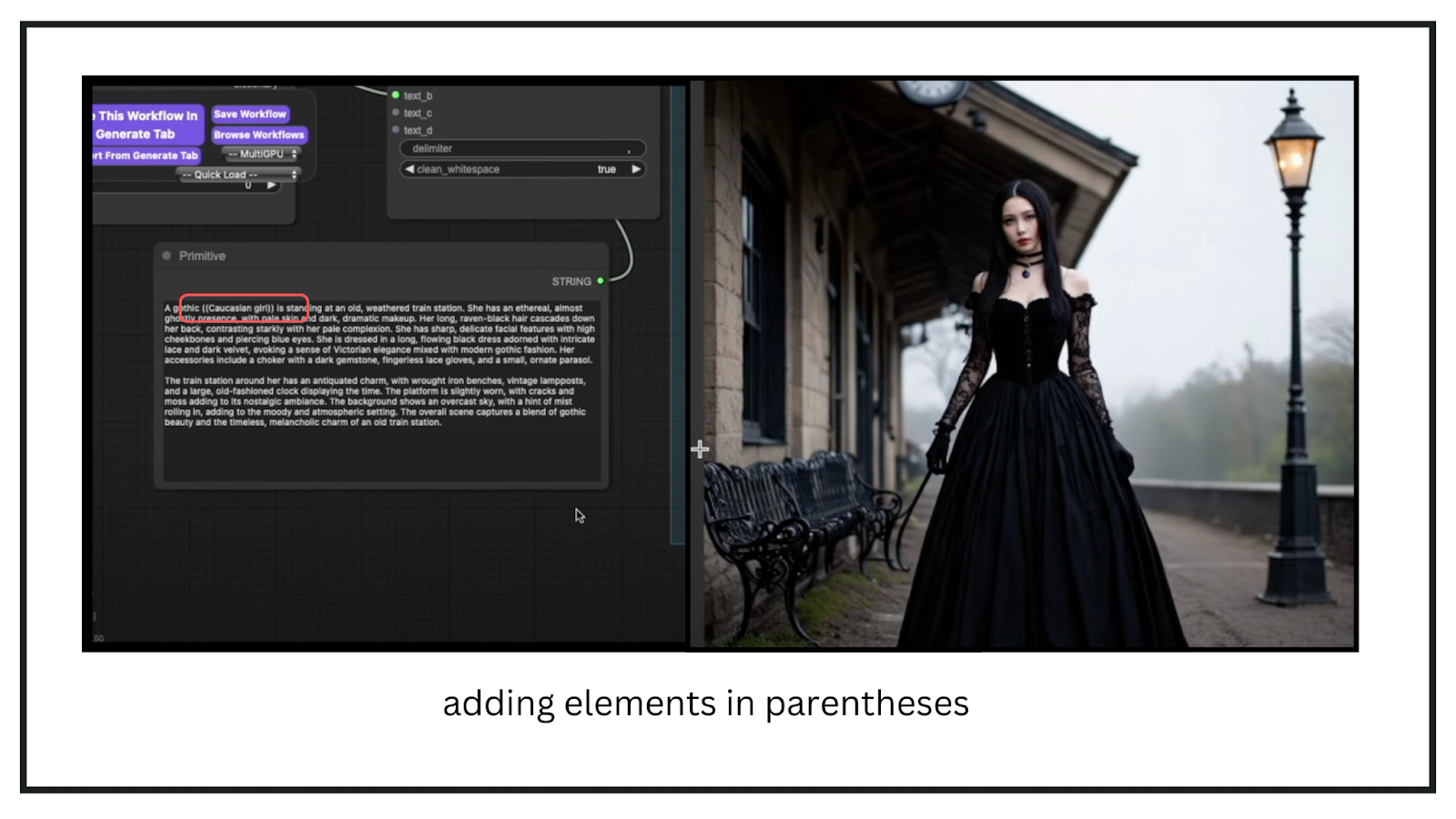
This demonstrates how creative we can get with the same prompt. By applying the prompt as a single text block into the CLIP encoder, which then feeds into our KSampler, we can achieve significantly improved results with Stable Diffusion 3.
Prompt Techniques with CLIPTextEncodeSD3 Node
The CLIPTextEncodeSD3 node is a powerful tool that optimizes how prompts are interpreted by Stable Diffusion 3. While my personal experimentation with it is limited, insights from the Stable Diffusion 3 Discord suggest specific practices for effective use.
First CLIP: Brief Subject Description: Begin with a concise description of your subject, which serves as the focal point of the image. For example, “a Gothic Caucasian girl standing at an old, weathered train station.”
Middle CLIP: Image Elements and Settings: In the second panel, introduce additional details such as camera settings, stylistic preferences, and any ethereal qualities you envision. This panel helps in refining the visual style and mood of the image. (example: captured in stunning high-definition with a Canon EOS-1D X Mark, 200 mm lens, f1.2.aperture)
Last CLIP: Detailed Environment Description: The third panel should contain a more elaborate description of the environment or setting, providing context and depth. For instance, elaborate on the characteristics of the weathered train station and the atmosphere it exudes.
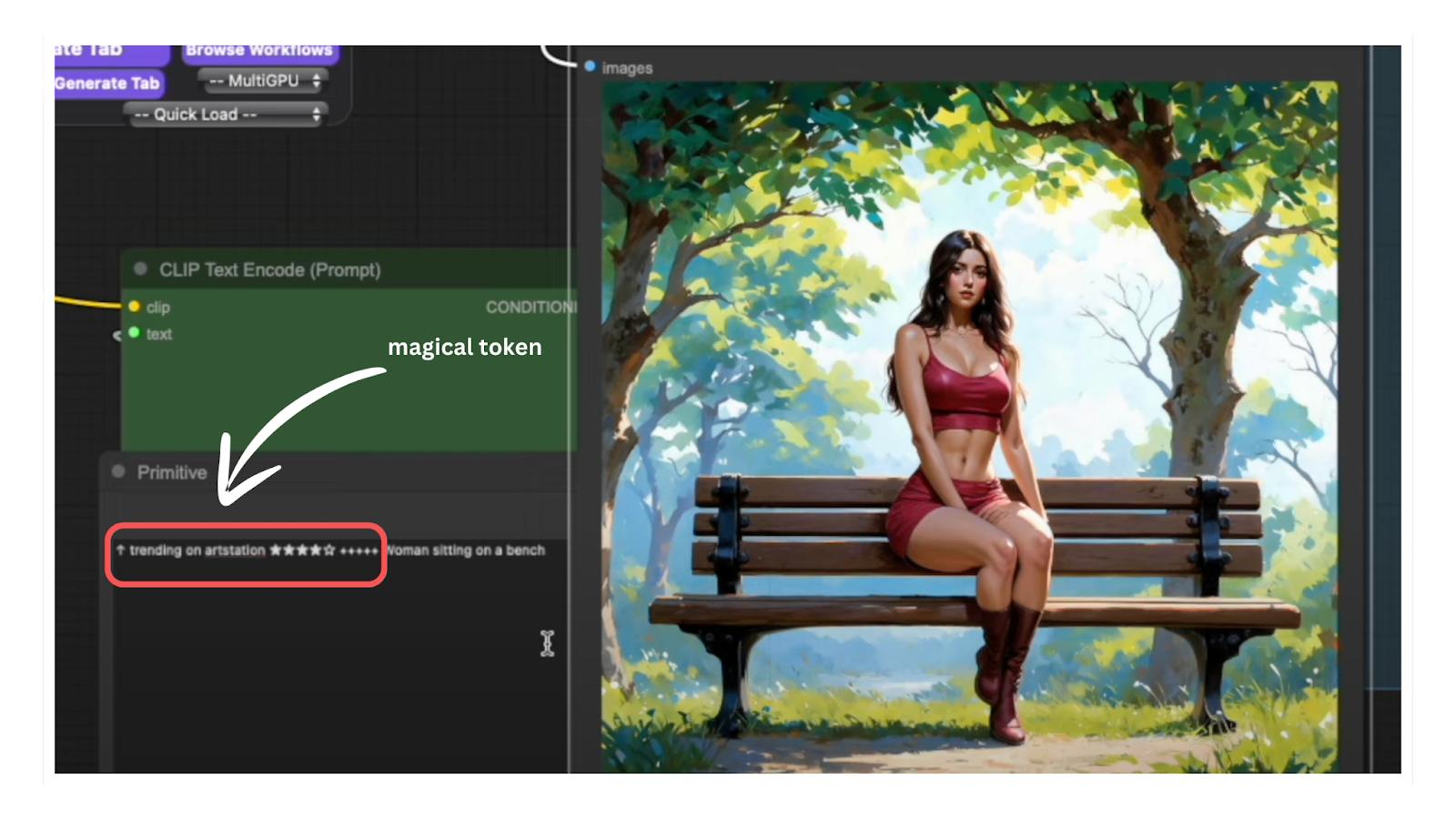
Enhancing Image Quality with Special Tokens
Begin with a detailed prompt: such as “woman sitting on a park bench” to provide comprehensive guidance to the model.
Apply Tokens Strategically: Simplify the prompt to “woman sitting on a bench” and incorporate special tokens at either the beginning or end. These tokens significantly improve anatomical accuracy and overall image quality.
Evaluate and Refine: Assess the results for enhanced anatomy and proportionality. Note any remaining stylized elements and adjust the prompt as needed to achieve the desired balance between realism and artistic interpretation
Generation with Prompt Scheduling
How to manipulate prompt scheduling to achieve desired results in Stable Diffusion 3:
- Set Up Prompt Scheduling: Utilize Stability AI’s default workflows on Hugging Face (https://huggingface.co/) to establish conditioning set time step ranges. This approach allows for the sequential application of different prompts during image generation.
- Example Application: Target a challenging scenario, such as creating an image of a woman lying on grass, which often yields unsatisfactory initial results with Stable Diffusion 3.
- Implement the Technique: Begin with a preliminary prompt that directs the model away from potential inappropriate imagery. For instance, use a detailed description like “a woman leaning against a dark green slime wall,” ensuring specificity to guide the model’s initial stages.
- Refine with ConditioningSetTimeStepRange: Input the initial prompt into ‘ConditioningSetTimeStepRange,’ setting it from 0.000 to 0.075 of the generation process. This primes the model with foundational elements while delaying more complex details.
- Gradual Transition to Detailed Prompt: From 0.075 to 1.000 of the process, introduce the complete, detailed prompt. For example, “In a serene, sun-dappled meadow, a young woman lies peacefully amidst a sea of lush emerald grass,” providing vivid specifics for enhanced visual fidelity.

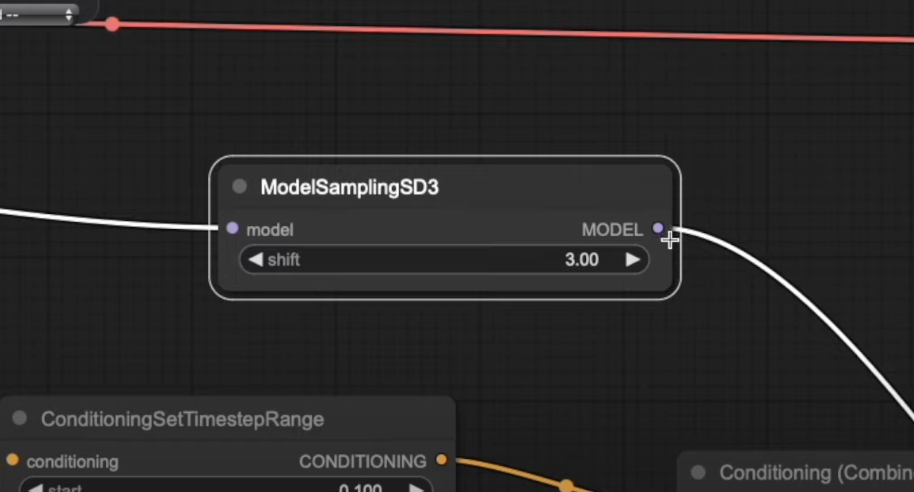
Image Quality with ModelSamplingSD3 Shift
using ModelSamplingSD3 Shift in Stable Diffusion 3:
- Understanding ModelSamplingSD3 Shift: Learn how this node influences denoising at varying resolutions, balancing the model’s focus between structural integrity and fine details. Higher shifts emphasize detail, while lower shifts prioritize structural clarity, ideal for resolutions near 1 megapixel.
- Implementing Image Enhancement: Start with an image previously generated in SDXL. Transition it to SD3 with a straightforward prompt like “portrait of a woman.” Adjust the denoise level carefully—set it higher for preservation of structural elements or lower for enhanced detail. For instance, a denoise level of 60% maintains structure while reducing noise, yielding a clean and visually appealing result.
- Refining with Specific Prompts and Resolutions: Experiment with different prompts to tailor the image’s artistic style. Lower the denoise level to 33% and include modifiers like “modern art” to enrich detail and aesthetic quality. Adjusting these parameters refines features like eyes and skin texture, elevating overall image fidelity.
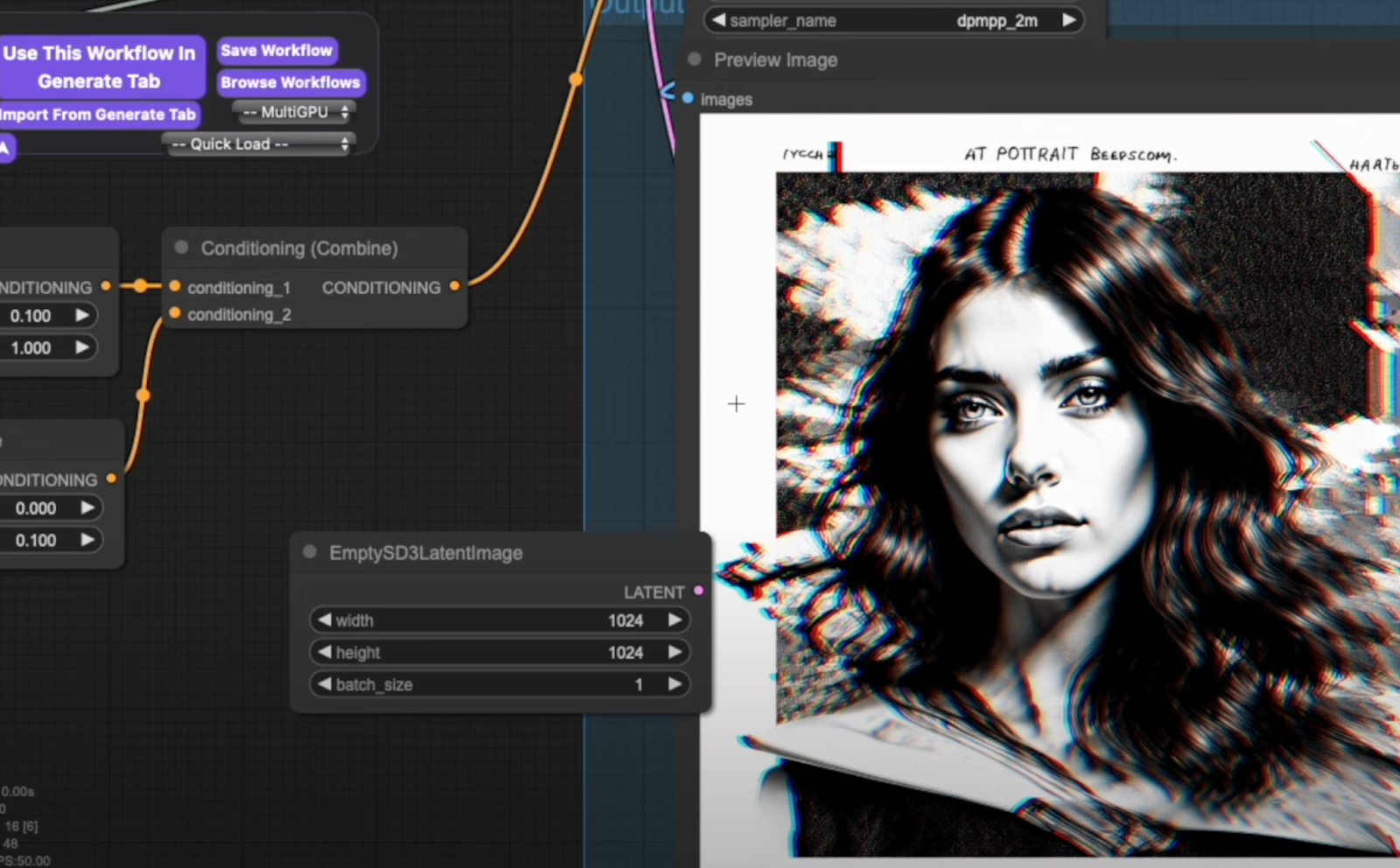
Enhancing Image Style with 4chan URLs (https://www.4chan.org/index.php)
Technique to influence image style using random 4chan URLs within Stable Diffusion 3:
- Practical Application: Start with a baseline image prompt like “portrait of a woman.” Observe the initial output quality, which serves as a benchmark for comparison.
- Implementing 4chan URLs: Enhance the prompt by appending a 4chan URL format like “4chan.com XYZ 24533U.” Notice significant alterations in the image style, such as distinct signatures or border effects, reflecting the influence of external references.
Result:
Conclusion:
Experimenting with these advanced techniques not only improves image fidelity but also expands the creative possibilities with Stable Diffusion 3. Whether you’re refining portraits, landscapes, or imaginative scenes, these tips are invaluable for achieving remarkable results.
Join the Community
Full Video: https://youtu.be/awJUry8AQu8?si=zmKNcH9Um32Dmu14
Website: Visit https://endangeredai.com for more resources.
Patreon: https://www.patreon.com/endangeredai